Principally, relational database systems have been optimized over several decades and represent a long heritage of performance, stability and reliability benefits. However, the decision of what persistence engine to use should always be a deliberate decision that fundamentally focuses on what the core requirements for the datastore actually are. A few key ones include the read/write characteristics of the application, the query and retrieval complexity, and not least of which are the production access patterns (what volume of reads/writes you're likely to see) to help inform decisions driven by the CAP Theorem.
In this post, my goal is to show what you can do with a "graph database" as a contrast to a traditional "relational" database. Relational databases split application domain into tables containing specific content of a certain type. For example, a table of Movies, with pointers (called foreign keys) that point to other entities in other tables. For example, you might link a "Movies" table with an "Actors" table by building a "Actor_Movie" table which contains a reference to the Actor table where that actor acted in the movie referenced in the Movie table.
But the problem of querying such relational tables efficiently for some kinds of queries represents a lot of complexity in the query/schema or moves a lot of the heavy lifting (read: time, effort, bugs) into the application domain of the programmer, which is patently the opposite intent of selecting a data persistence engine which is supposed to elegantly solve some of your problems without reinventing the wheel. A graph database takes a different approach allowing you to place all of your "nouns" (actors, movies, etc.) as "nodes" in a graph, and then allowing multiple "edge types" or arrows that are drawn between the "nouns" representing a given relationship between the nodes. For example, in a movie dataset, nodes could be movies, actors, directors; edges could be "acted_in", "directed". Further, the edge "acted_in" could contain an attribute of the role (actor(Tom Hanks) acted_in(as "Forrest Gump") in movie(Forrest Gump)).
If you want to get a sample dataset running to follow along, continue; otherwise, scroll down to the "Prepare Data" section to fast forward to a demo.
Prerequisites
On my Mac, preparing the prerequisites, installing the software, preparing the data, and playing with it was super easy (<10 minutes) using Brew. If you've already got brew, Java or your own dataset, or your platform has different prerequisites, skip the appropriate steps here. Your mileage will vary, but ultimately, use your package manager to (or manually) install Neo4J.
-2. Install Brew package manager.
$ ruby -e "$(curl -fsSL https://raw.github.com/Homebrew/homebrew/go/install)" $ brew doctor
-1. Install the Java 7 SDK
Download from Oracle if you don't already have it.
0. Download the Cineasts dataset
$ cd /tmp $ curl -O http://example-data.neo4j.org/files/cineasts_12k_movies_50k_actors.zip
Install
1. Install Neo4j
$ brew install neo4j2. Upgrade dataset to Neo4j 2.0.0 automatically on startup (on first start)
$ vi /usr/local/Cellar/neo4j/2.0.0/libexec/conf/neo4j.propertiesSubstitute your favorite text editor if you don't know vi.
(if you didn't use brew, you'll need to find your properties file)
Uncomment the line that says:
#allow_store_upgrade=true
3. Place the dataset where Neo4J looks for it.
$ cd /usr/local/Cellar/neo4j/2.0.0/libexec/data/ $ mkdir graph.db $ cd graph.db $ mv /tmp/cineasts_12k_movies_50k_actors.zip . $ unzip cineasts_12k_movies_50k_actors.zip
(optional, you might keep it around to reset your data)
$ rm cineasts_12k_movies_50k_actors.zip
4. Start neo4j
$neo4j start�Prepare Data
The dataset lacks labels, which I find makes querying a bit harder, so let's fix it.
1. Open the neo4j UI:
http://localhost:7474/browser/.
2. Run the following queries which adds labels to the two distinct types we care about in the dataset... they take a few seconds as it does about 62,000 writes on the dataset to add labels.
MATCH (n) WHERE n.__type__ = "org.neo4j.cineasts.domain.Movie" SET n:Movie MATCH (n) WHERE n.__type__ = "org.neo4j.cineasts.domain.Person" SET n:PersonThis gives you a sense of Cypher, the SQL-like query language for Neo4J.
Queries
Consider the following query:
MATCH (n:Person {name:"Jack Nicholson"}) RETURN n
The way to read this is,
"Match a node, and call it "n" that has a label of Person, whose attribute called "name" is "Jack Nicholson", and return that node "n". This is the equivalent of a basic single row select in a relational database.
Now let's stretch the bounds of what you can easily do with a relational database. What if we wanted to answer the "Kevin Bacon" question between Kevin Spacey and Meg Ryan? Or between he and Jack Nicholson? Easy!
MATCH p=shortestPath( (s:Person {name:"Kevin Spacey"})-[*]-(r:Person {name:"Meg Ryan"}) ) RETURN p
MATCH p=shortestPath( (s:Person {name:"Kevin Spacey"})-[*]-(n:Person {name:"Jack Nicholson"}) ) RETURN p
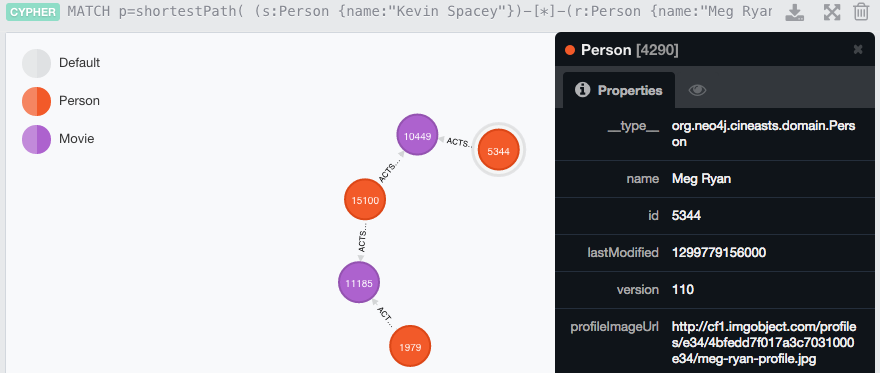
However, this just returns an answer-- what if you want all of them?
MATCH p=allShortestPaths( (s:Person {name:"Kevin Spacey"})-[*]-(n:Person {name:"Jack Nicholson"}) ) RETURN p
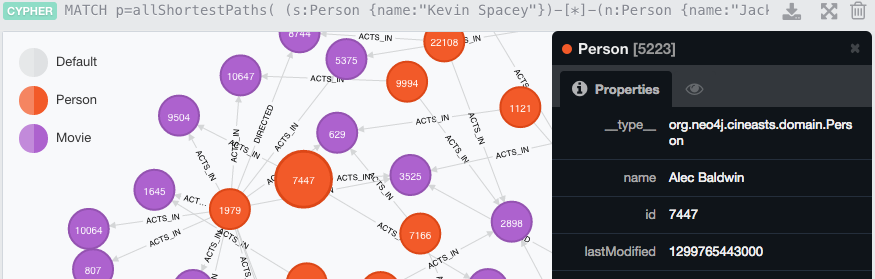
On your Neo4J UI, double click nodes to expand, click nodes to see properties on that node or on that edge.
As I started to think about what kind of queries to demonstrate, I thought of some Hollywood trivia. For example, I know that Francis Ford Coppola and Nicholas Cage are related (uncle/nephew). What movies did FFC direct that NC acted in? Sounds difficult? With Cypher it's easy:
MATCH p=allShortestPaths( (s:Person {name:"Francis Ford Coppola"})-[*]-(n:Person {name:"Nicolas Cage"}) ) RETURN p
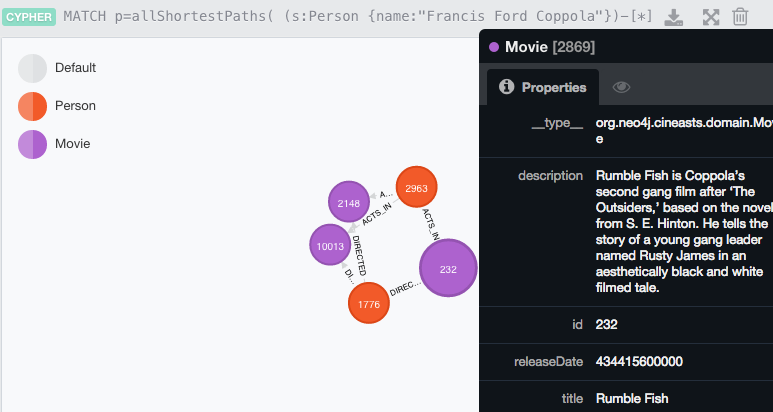
Astute readers might point out that this is a less than elegant query because it shows all relationships-- that is, it would return a movie that both NC and FFC both acted in. Fixing that is easy:
MATCH (nc:Person {name:"Nicolas Cage"})-[:ACTS_IN]->(m)<-[:DIRECTED]-(ffc:Person {name:"Francis Ford Coppola"}) RETURN m
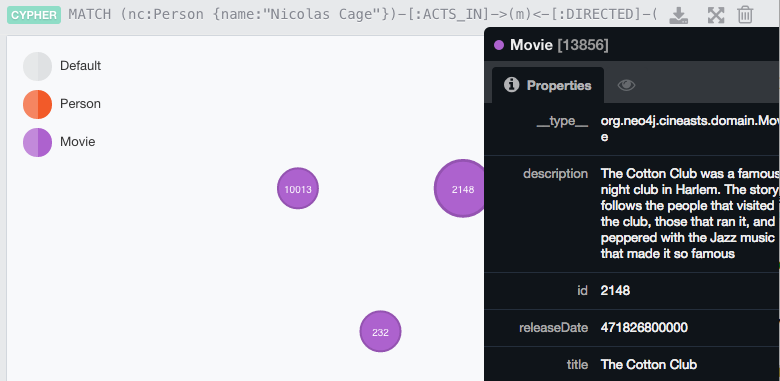
Expressing that same logic in a relational database is not quite as easy and is likely to tax the hardware its run on much more than a graph database for equivalent performance.
And that's the key takeaway-- to do the job most efficiently, you need to pick the right tool for the job, and that means having both relational and "post-relational" data storage solutions in your toolchest.
