A sprint demo (a.k.a. a sprint review) is one of the most potentially impactful meetings a team can conduct. The following tips can help you increase the impact and relevance of your demos to not only stakeholders attending your demos, it can help remind your own team what impact their work has on the broader initiatives within the company.
Outcome Desired
Let’s start by defining the ideal outcome we’d love to see as a scrum team for a demo meeting.
First, we want our demos to be well attended. That is, what’s the point of the demo if nobody outside of the team shows up? (Are your sprint demos well attended? If not, you might encourage your stakeholders and invitees to ask if some of the tips offered here might reignite their or their reports to begin attending your demos!)
Second, we want our attendees to be highly engaged. There is some circular logic here, of course. If the demo isn’t engaging, then people are likely to stop attending. To engage an audience, we need to speak to them in the language and in the context that makes the most sense to them.
Incidentally, the five levels of Agile planning map to the language and context that stakeholders should be keenly attuned to. (Why? Because if they are not, it is likely because there is a disconnect between corporate priorities and your agile planning. If they are not keenly attuned to each other, there may be larger issues with your organization’s adoption of agile/scrum that are worth addressing first)
The desired outcome of a sprint demo, is not merely to demonstrate the work done, we must to paint the picture of the context of this work in relation to the sprint theme, the release cycle, the product roadmap, and what aspect of the product/organizational vision it contributes to.
Good News, Bad News
The good news is, if your organization is consistently improving its execution of the five levels of planning, many of these pieces may already be in place. The bad news is, if there are obstacles in those planning processes, you’ll have your work cut out for you to achieve the ideal outcome. Implementing the right continuous improvement initiatives will depend on whether the five levels of planning is a root cause of an ineffective sprint demo (deeper work required), or if the root cause is merely a small shift in how you conduct a sprint demo (easy fix).
Marching to Mars
Imagine a fictional corporation called “CosmosY” presenting a demo of a rocket launch. Let’s consider two approaches to the presentation:
Scenario A: This sprint, we launched our SN10 rocket with the goal of launching a rocket to 10km, manage the aerodynamic forces as it falls back to earth, and if possible, land it back on its launch pad. As we will now demonstrate, we launched, hovered, and controlled the fall, but came down harshly on the landing, causing the legs to crumple, and for the vessel to lose its integrity and explode minutes after landing.
Scenario B: Our vision is to be the first company to make humankind a multi-planetary species by establishing the first colony on Mars by 2026. Along the way, CosmosY is competing for a NASA contract to land a man and woman on the moon by 2024. In order to compete for this business, we must achieve design review approval by NASA consisting of three primary capabilities by end of 2021: Launch, hover in earth atmosphere at 10K elevation, and controlled landing.
Last sprint, we demonstrated the launch and hover capability, but discovered issues with engine reliability after the hover maneuver. Thus, the objective of this sprint was to prove we fixed the engine issues after hovering at 10K feet, and then to test aerodynamic integrity during the free fall prior to landing. Our stretch goals included returning to vertical after horizontal free fall by reigniting the rockets, and if successful, test a prototype design for the landing legs, which we plan to show NASA in our design review this summer.
Why is Scenario B better? It’s not merely because it is longer. Of course that is necessary because it reminds everyone “where are we going and why?” (Scrum Planning Outcome: Vision). It gives context for the market/competitive forces/timelines (Scrum Planning Outcome: Roadmap). It provides context for what was recently completed, what obstacles we need to overcome, and what we set out to do (Scrum Planning Outcome: Release Plan/Sprint Theme/Sprint Goals).
It also opens the door to several other aspects that can really invigorate sprint demos and agile teams in an organization, particularly if this model is followed by all teams (and if those teams attend other team demos): It provides sufficient clarity to help other teams understand how they can react/adapt to the discoveries.
Do the Right Work; Then Do the Work Right
It’s a rather simple flowchart to have effective Sprint Demos; how much effort a team must put in to make them highly engaging and useful to stakeholders, though, depends on how mature your agile processes are across the organization. If you can answer “yes” to all of the questions posed, then you’ve got all the foundational pieces; all that is necessary is perhaps some minor tweaks of managing your stories (e.g. ensuring that you’re leveraging your tools like Jira to effectively to map stories to releases and epics to make presenting the stories and a sprint’s work with less effort with built in reports), and a basic sprint presentation template that reminds you to remind the ties to vision->roadmap->releases->sprint themes in each demo.
And if you answered “no” to any of the flowchart questions, the good news is that you may have just discovered what level of planning needs improvement to lead to more impactful sprint demos that engage and excite stakeholders at all levels of the organization!
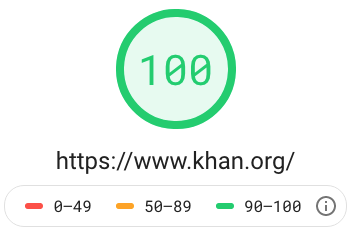 Avid readers will notice that I recently launched a rebranding of my personal website. Unlike many other professionals for whom building Websites is ancillary to their primary business, for me, building web applications that are scalable, perform, and offer the best in security, accessibility and usability are core strengths.
Avid readers will notice that I recently launched a rebranding of my personal website. Unlike many other professionals for whom building Websites is ancillary to their primary business, for me, building web applications that are scalable, perform, and offer the best in security, accessibility and usability are core strengths.


