Over the decades of leading and transforming software engineering teams, I've come to believe that the essence of any company's culture lies not in its statements, but in its actions. In the best circumstances, there is no dissonance between what is lived as an employee and what is published as "company values" or "core values." However, in too many cases, that gap is tangible and undermines morale and trust in the organization.
Ultimately, a company is just a shell devoid of culture without its people. For values to be meaningful, they must be embodied by their people, especially by their leadership. When a company posts its values, that is a clear license for everyone to live by them.
Failing to embody these values is a failure of personal responsibility. Even if you rise to the occasion and receive criticism, it's a learning experience. Growth comes from applying the values with integrity and understanding where you fell short, just as it does when you hit the mark and realize there is a larger leadership vacuum.
For leaders who want to lead with integrity and build psychological safety within their teams, remember this principle: "Nobody needs permission to live the company values." Culture thrives when leadership inspires by example; be the one to embody the values you wish to see!
Wed, 26 Jun 2024
Sun, 14 Mar 2021
High Impact Sprint Demos
A sprint demo (a.k.a. a sprint review) is one of the most potentially impactful meetings a team can conduct. The following tips can help you increase the impact and relevance of your demos to not only stakeholders attending your demos, it can help remind your own team what impact their work has on the broader initiatives within the company.
Outcome Desired
Let’s start by defining the ideal outcome we’d love to see as a scrum team for a demo meeting.
First, we want our demos to be well attended. That is, what’s the point of the demo if nobody outside of the team shows up? (Are your sprint demos well attended? If not, you might encourage your stakeholders and invitees to ask if some of the tips offered here might reignite their or their reports to begin attending your demos!)
Second, we want our attendees to be highly engaged. There is some circular logic here, of course. If the demo isn’t engaging, then people are likely to stop attending. To engage an audience, we need to speak to them in the language and in the context that makes the most sense to them.
Incidentally, the five levels of Agile planning map to the language and context that stakeholders should be keenly attuned to. (Why? Because if they are not, it is likely because there is a disconnect between corporate priorities and your agile planning. If they are not keenly attuned to each other, there may be larger issues with your organization’s adoption of agile/scrum that are worth addressing first)
The desired outcome of a sprint demo, is not merely to demonstrate the work done, we must to paint the picture of the context of this work in relation to the sprint theme, the release cycle, the product roadmap, and what aspect of the product/organizational vision it contributes to.
Good News, Bad News
The good news is, if your organization is consistently improving its execution of the five levels of planning, many of these pieces may already be in place. The bad news is, if there are obstacles in those planning processes, you’ll have your work cut out for you to achieve the ideal outcome. Implementing the right continuous improvement initiatives will depend on whether the five levels of planning is a root cause of an ineffective sprint demo (deeper work required), or if the root cause is merely a small shift in how you conduct a sprint demo (easy fix).
Marching to Mars
Imagine a fictional corporation called “CosmosY” presenting a demo of a rocket launch. Let’s consider two approaches to the presentation:
Scenario A: This sprint, we launched our SN10 rocket with the goal of launching a rocket to 10km, manage the aerodynamic forces as it falls back to earth, and if possible, land it back on its launch pad. As we will now demonstrate, we launched, hovered, and controlled the fall, but came down harshly on the landing, causing the legs to crumple, and for the vessel to lose its integrity and explode minutes after landing.
Scenario B: Our vision is to be the first company to make humankind a multi-planetary species by establishing the first colony on Mars by 2026. Along the way, CosmosY is competing for a NASA contract to land a man and woman on the moon by 2024. In order to compete for this business, we must achieve design review approval by NASA consisting of three primary capabilities by end of 2021: Launch, hover in earth atmosphere at 10K elevation, and controlled landing.
Last sprint, we demonstrated the launch and hover capability, but discovered issues with engine reliability after the hover maneuver. Thus, the objective of this sprint was to prove we fixed the engine issues after hovering at 10K feet, and then to test aerodynamic integrity during the free fall prior to landing. Our stretch goals included returning to vertical after horizontal free fall by reigniting the rockets, and if successful, test a prototype design for the landing legs, which we plan to show NASA in our design review this summer.
Why is Scenario B better? It’s not merely because it is longer. Of course that is necessary because it reminds everyone “where are we going and why?” (Scrum Planning Outcome: Vision). It gives context for the market/competitive forces/timelines (Scrum Planning Outcome: Roadmap). It provides context for what was recently completed, what obstacles we need to overcome, and what we set out to do (Scrum Planning Outcome: Release Plan/Sprint Theme/Sprint Goals).
It also opens the door to several other aspects that can really invigorate sprint demos and agile teams in an organization, particularly if this model is followed by all teams (and if those teams attend other team demos): It provides sufficient clarity to help other teams understand how they can react/adapt to the discoveries.
Do the Right Work; Then Do the Work Right
It’s a rather simple flowchart to have effective Sprint Demos; how much effort a team must put in to make them highly engaging and useful to stakeholders, though, depends on how mature your agile processes are across the organization. If you can answer “yes” to all of the questions posed, then you’ve got all the foundational pieces; all that is necessary is perhaps some minor tweaks of managing your stories (e.g. ensuring that you’re leveraging your tools like Jira to effectively to map stories to releases and epics to make presenting the stories and a sprint’s work with less effort with built in reports), and a basic sprint presentation template that reminds you to remind the ties to vision->roadmap->releases->sprint themes in each demo.
And if you answered “no” to any of the flowchart questions, the good news is that you may have just discovered what level of planning needs improvement to lead to more impactful sprint demos that engage and excite stakeholders at all levels of the organization!
Comments are closed for this story
Tue, 20 Oct 2020
A Taxonomy for Thinking About Technology Organizations
A foundational taxonomy construct that I have found useful in leading Technology organizations is "People, Process, Technology". In mathematical form, it can be summarized into a simple equation:
That is, a technology organization's capabilities (C) is proportional to the capabilities it can harness from its People (Pe : who they are, what they are capable of), Processes (Pr repeatable methods and procedures the organization leverages to make and execute decisions), and Technology (T, or past and present investments in tools and systems that simplify tasks or otherwise amplify the power of the people and processes in the organization).
The reason I think this is a notable insight and not merely a truism is that it can help contextualize where an organization finds itself either across the board, or when investing in a particular area of the business. For example, a startup (or a new division or product team in an established organization) may have made some exceptional hires, but if it has yet to formalize any accelerating Processes or yet to invest in any significant Technology must rely on the first factor (People) to get anything done. Its challenges will be to introduce Process and Technology that amplify and accelerate what its people can do.
Meanwhile, an established organization with strong productivity (e.g. existing products that sustains the business) is likely to have strong Processes, but if it is growing, may hit scale limits on its Technology or struggle with training and sustaining its practices along with its People growth.
Organizations struggling due to market or competitive demands may find its Technology investments are outdated and don't support Processes that could accelerate the organization further.
Knowing which factors need investment on which teams is crucial to making arguments for budgeting, prioritization, and presenting the kinds of investments which maximize the organization's overall capabilities.
How are your investments in People, Process and Technology serving your organization's Capabilities?
That is, a technology organization's capabilities (C) is proportional to the capabilities it can harness from its People (Pe : who they are, what they are capable of), Processes (Pr repeatable methods and procedures the organization leverages to make and execute decisions), and Technology (T, or past and present investments in tools and systems that simplify tasks or otherwise amplify the power of the people and processes in the organization).
The reason I think this is a notable insight and not merely a truism is that it can help contextualize where an organization finds itself either across the board, or when investing in a particular area of the business. For example, a startup (or a new division or product team in an established organization) may have made some exceptional hires, but if it has yet to formalize any accelerating Processes or yet to invest in any significant Technology must rely on the first factor (People) to get anything done. Its challenges will be to introduce Process and Technology that amplify and accelerate what its people can do.
Meanwhile, an established organization with strong productivity (e.g. existing products that sustains the business) is likely to have strong Processes, but if it is growing, may hit scale limits on its Technology or struggle with training and sustaining its practices along with its People growth.
Organizations struggling due to market or competitive demands may find its Technology investments are outdated and don't support Processes that could accelerate the organization further.
Knowing which factors need investment on which teams is crucial to making arguments for budgeting, prioritization, and presenting the kinds of investments which maximize the organization's overall capabilities.
How are your investments in People, Process and Technology serving your organization's Capabilities?
Comments are closed for this story
Mon, 28 Sep 2020
Running Up The (A11y, Performance, SEO, Security) Score
 Avid readers will notice that I recently launched a rebranding of my personal website. Unlike many other professionals for whom building Websites is ancillary to their primary business, for me, building web applications that are scalable, perform, and offer the best in security, accessibility and usability are core strengths.
Avid readers will notice that I recently launched a rebranding of my personal website. Unlike many other professionals for whom building Websites is ancillary to their primary business, for me, building web applications that are scalable, perform, and offer the best in security, accessibility and usability are core strengths.
In the hopes that it inspires others to drive for better outcomes on their website, I share the techniques I used to achieve the performance I did. Beyond just turning some dashboard widget green from yellow or red, when compared against the performance of the site I had, how quickly the website loads speaks for itself.
Note that these techniques are invariant of site complexity, features, or size. It's merely a difference in scale of time and resources that needs to be invested to achieve similar outcomes; I will merely concede that some sites may have diminishing returns. If these techniques are over your head, then pass them on to your Web team as a checklist to implement, or reach out and I can help guide you towards people who can help. With those caveats out of the way, let's proceed!
Here are the objectives I set for my site's capabilities:
- Perform at or above the 95th percentile of websites
- No glaring HTML errors that can degrade experience or cause browser rendering issues
- It must use best practices to deliver content efficiently
- It must have basic SEO that makes the site readable and navigable by bots
- It must have basic Accessibility that makes the site readable and navigable by people of varying abilities
- Provide the best SSL/security options available
If I were to delve into every detail of every thing I did to achieve this outcome, this post would be two to three times longer than it already is. Rather, I will briefly outline what I did, why I did it, and provide some reasons why it's worth the effort.
Site Performance
To get my site to perform at 98th percentile or better (of sites Google generally crawls) required using a few techniques. The first and most crucial was to embrace a newer, faster, binary protocol for the Web called HTTP2. This is a server technology, so like the security section mentioned below, to make these changes, you need to either configure your web server (typically software with names like Apache, Nginx, or IIS) to support this faster protocol. And if you're told your server can't support this protocol, chances are it is so out of date, it indicates that your hosting capabilities are woefully out of date (by over 4-5 years) and need attention.One way to understand why HTTP2 is so much faster is to imagine if airlines had the ability to allow people to board the plane as they arrive at the gate instead of having a rush when boarding is announced. To pull this off, airlines would have to dedicate a gate to a single airplane, and keep the plane at the gate for the entire day of the flight. The strategy HTTP2 applies uses the same kinds of principles.
A secondary factor is to use a CDN (a "content delivery network" which is a strategy to locate assets your site needs at various globally distributed locations to ensure they can be loaded quickly for a visitor regardless of where they live) for just about every resource you can, and to ideally use a single one to minimize DNS lookups. Initially, I used several libraries (PureCSS and FontAwesome), and loaded them from multiple CDNs, but when I discovered that CloudFlare has all of the libraries I needed, I was able to use just one.
A third factor was to recognize that my largest assets, like most websites, was the size and number of images I was loading. There are lots of apps and services that shrink down image sizes, some lossy (affecting image quality) and some not. I personally used ImageOptim which happens to have a Mac app as well as a web service. The idea is, if a 500KB image and a 50KB image look indiscernible to your users, the 50KB one can be delivered 10 times faster. Every web site's workflow should include optimizing its images. Every graphic designer who works on the Web should know enough about image technology to know if a JPG, PNG or otherwise is the better medium to use, and how to optimize the settings to deliver the image in a reasonably efficient way.
The final strategy was to minimize unnecessary requests to various servers. There's a lot of small things I did to achieve these objectives, so I won't go into great detail on every one, as much as to give some hints about things you can do. All of these techniques are evident to HTML experts, so "view source" on my website will illustrate them in full. Here's a brief summary of what I did and the tools to pull it off.
- Eliminate favicon.ico calls to my server by delivering it with a data: URL (see my <head> tag).
- Use tools like Icomoon.io and FontSquirrel and CloudConvert to build a custom font, then base64 encode it and place it inline into my stylesheet for the "brands", and other svg style assets you see in various titles and footer elements on my site.
(Many websites load custom fonts to add stylistic elements, but the asset sizes of the full font are pretty huge; instead, you can create your own custom font that include only the svgs you need and then use an encoding called base64 to use data: URLs to deliver that custom font)
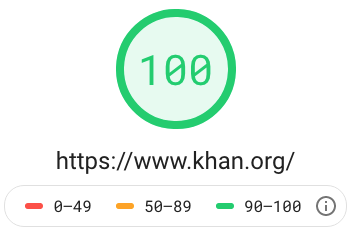
After using these and other minor techniques that the Google LightHouse Chrome plugin suggested, my site was quickly as fast or faster than 99% of all websites.
See Google's PageSpeed/LightHouse score for khan.org! Then run your own site to see how your brand/company does?
Best Practices
Google's Chrome plugin also provides other tools for Accessibility, Best Practices, and SEO. My suggestion here is to invest just enough time to ensure all of these get to a "green" status since they are all basically table stakes for a modern Web site to achieve a modicum of machine and human readability.Accessibility
I gave this a special section because I used a separate tool to improve my site's a11y score. Namely, the "Axe". This free extension from Deque will give you insights on where your content is not easily readable by accessibility-challenged visitors. While this is not a guarantee of a fully accessible site, you've got no hope if even the automated tools are telling you your site is unfriendly to such visitors.In fact, the biggest challenge I faced was ensuring my site had sufficient contrast in various site features, and grappling with the biggest challenge I had forced me to reckon with a design problem on my site until I had an objectively better strategy for that page component.
As these images show, what often lurks under an Accessibility quagmire is actually poor design choices. My experience suggests that if you fix your accessibility impediments, you'll actually end up with an universally better design!


It goes to show that doing the right thing for one reason, ends up being the right thing for many other reasons. My Accessibility journey required fixing a lot of color contrast issues, so I thought I'd share the tool that helped me select more readable colors from my default color picks.
While I used Axe to remediate the bulk of my issues, the WAVE tool has an online validator that makes it easy to check a site.
See The WAVE tool's score for khan.org! Then run your own site to see how your brand/company does?
SSL/Security
To deliver the site with the best security options available, you should ensure your site is delivered via https. Once considered optional because it was pricy and complicated, today all of those objections and excuses have been eliminated. The Let's Encrypt project has made getting a certificate free, and tools like SSL Labs can show you what protocols you support and give your web server administrator (the guy in your web team that knows what Apache, nginx or IIS is and how to configure it properly) the cues they need to enable the right protocols to get a A+.See SSL Labs' score for khan.org! Then run your own site to see how your brand/company does?
HTML Validation
Last, but not least, writing semantic, properly validating HTML can speed up rendering because you're speaking the language browsers expect you to speak, rather than using HTML dialects browsers don't know how to render. If your site doesn't pass a validation check from the W3C's validator, addressing the issues has the added benefit of reminding how to write proper HTML.See W3C's score for khan.org! Then run your own site to see how your brand/company does?
In the end, these simple tools can help any site, and brand, and business improve the usability, functionality, performance, design, and compatibility of their online presence. Whether you are building a simple personal profile page, or a full scale professional business/brand presence, I'm curious if these, or other tips and tools, helped address what your biggest gaps were?
Comments are closed for this story
Tue, 22 Sep 2020
My Leadership Style
One of the benefits of gaining years of experience is the principles that you discover in the journey of how to approach challenges. Given we are not defined merely by our work lives, what has shaped my leadership style originates from all aspects of my life experience.
The six aspects that I think characterize my leadership style are:
In retrospect, starting a computer club to address an awareness gap of campus resources that students and staff could leverage, lobbying for a technology fee when presented with budgetary restrictions to give every student access to those resources, and building my university’s first web site back in 1994, I think he saw what took me a few years to realize about myself. I love solving problems, and every organization faces the challenges of needing to solve problems with limited resources.
Introducing rigor into the software development process not only produces better business and technical outcomes, it brings structure, order and focus to the software professionals who may have only been lacking for software leadership to bring that attribute to their own craft. In other words, establishing these high standards can often serve to attract and keep top talent because they see their own professional skills and maturity grow.
No data point is more crucial than listening to, and taking action on, the challenges your team members are facing, because they are the ones who, as Theodore Roosevelt put it, are "in the arena." Your team is the one whose faces are "marred by dust and sweat and blood", it is they "who strives valiantly; who errs, who comes short again and again, because there is no effort without error and shortcoming; but who does actually strive to do the deeds; who knows great enthusiasms, the great devotions". It is they who are engaged in the "worthy cause; who at the best knows in the end the triumph of high achievement, and who at the worst, if [they fail], at least fails while daring greatly".
To me, this quote beckons software leaders to heed the call of servant leadership. Our teams enter the arena to grapple with the minotaur of the challenges we place before them. It compels me to see, hear, and experience their battles, and find every opportunity to unblock and resolve their impediments. Doing anything less sends a signal of mediocre commitment to our shared cause, and tepid appreciation for their willingness to enter the ring in pursuit of the noble challenges I would have placed before them.
Some of my most remarkable career accomplishments came not merely from identifying and bringing attention to problems, but to find creative solutions that fit the time, resource and budget constraints we had to address them. Collaborating with and inspiring my teams to achieve similar outcomes is not only a great outcome for the organization, it is deeply rewarding on any team member’s career journey, and in turn, a great way to drive engagement and retention of highly skilled technical staff.
In any sufficiently ambitious and worthwhile endeavor, articulating the vision, and building buy-in for it from your team are table stakes to seeing them realized.
The natural antidote to cynicism or apathy for me has been, simply, tenacity. The easy way to make every effort a winning gambit, is to never stop trying, never stop learning, and to keep striving for excellence as a moral imperative.
These characteristics are so closely inter-related for me, that they feel like facets to a singular concept, which because it lacks a commonly known label, warrants articulating them as distinct styles of leadership. For the sake of giving this collection a label, I might offer calling this style "Progressive Humanist Leadership".
The six aspects that I think characterize my leadership style are:
- Entrepreneurial Spirit: How to make a big impact with limited resources.
- High-Standards: Data-informed rationale to justify investing in continuous improvement practices.
- High Engagement: Credibility through listening to your team, and serving their needs.
- Creativity: Inspirational leadership is fundamentally creative, and encourages learning.
- Inspiration: Vision and buy-in to initiatives to see it realized are table stakes.
- Tenacity: When excellence is a moral imperative, we keep iterating until we reach our goal.
Entrepreneurial Spirit
When one of my favorite professors mentioned that he could see me (then a twenty-year-old college junior) as the founder or cofounder of a company I thought he had mistaken me for someone more courageous or self-confident.In retrospect, starting a computer club to address an awareness gap of campus resources that students and staff could leverage, lobbying for a technology fee when presented with budgetary restrictions to give every student access to those resources, and building my university’s first web site back in 1994, I think he saw what took me a few years to realize about myself. I love solving problems, and every organization faces the challenges of needing to solve problems with limited resources.
High Standards
The difference between a software engineer and a software developer is that software engineers are aware of the science and method behind building scalable, secure, performing, usable and accessible software. Whereas a developer can pull together something functional, an engineer can build something fit for purpose.Introducing rigor into the software development process not only produces better business and technical outcomes, it brings structure, order and focus to the software professionals who may have only been lacking for software leadership to bring that attribute to their own craft. In other words, establishing these high standards can often serve to attract and keep top talent because they see their own professional skills and maturity grow.
High Engagement
A facet closely related to High Standards, any sufficiently ambitious opportunity will present challenges. Any scientific, fact and evidence-based management approach is based on the premise that business systems are like any scientific system: one must observe the system’s conditions, propose and implement a change to the system, and inspect the outcome. Rinse/repeat until the outcomes expected emerge and inject learning and adaptation in each cycle to reach an optimum state.No data point is more crucial than listening to, and taking action on, the challenges your team members are facing, because they are the ones who, as Theodore Roosevelt put it, are "in the arena." Your team is the one whose faces are "marred by dust and sweat and blood", it is they "who strives valiantly; who errs, who comes short again and again, because there is no effort without error and shortcoming; but who does actually strive to do the deeds; who knows great enthusiasms, the great devotions". It is they who are engaged in the "worthy cause; who at the best knows in the end the triumph of high achievement, and who at the worst, if [they fail], at least fails while daring greatly".
To me, this quote beckons software leaders to heed the call of servant leadership. Our teams enter the arena to grapple with the minotaur of the challenges we place before them. It compels me to see, hear, and experience their battles, and find every opportunity to unblock and resolve their impediments. Doing anything less sends a signal of mediocre commitment to our shared cause, and tepid appreciation for their willingness to enter the ring in pursuit of the noble challenges I would have placed before them.
Creativity
No sufficiently complex system was built in a vacuum. Whether it was an inventor like Kwolek, Bell & Latimer, Goodyear, or Edison, whether it was the intellectual and reasoned insights of Einstein, Hawking or Helen Quinn, the realm of science and engineering, as problem solving craft, are never far separated from deeply creative thinking.Some of my most remarkable career accomplishments came not merely from identifying and bringing attention to problems, but to find creative solutions that fit the time, resource and budget constraints we had to address them. Collaborating with and inspiring my teams to achieve similar outcomes is not only a great outcome for the organization, it is deeply rewarding on any team member’s career journey, and in turn, a great way to drive engagement and retention of highly skilled technical staff.
Inspiration
In saying "nothing great was ever achieved without enthusiasm", I think Ralph Waldo Emerson meant not only that you need enthusiasm to produce great work, but that also any sufficiently challenging endeavor is going to tap out finite resources of grit or tenacity. After all, if the struggle isn’t worth struggling for, then why are we working so hard for the achievement?In any sufficiently ambitious and worthwhile endeavor, articulating the vision, and building buy-in for it from your team are table stakes to seeing them realized.
Tenacity
One concept many ancient Greek philosophies had in common was the concept of "virtue". While there was no unifying philosophy among the ancient city states, one cultural term ἀρετή ("aręte"), transcended the differences between the philosophical perspectives. While this word had many meanings even then, I’ve internalized this word to mean "striving for excellence as a moral imperative".The natural antidote to cynicism or apathy for me has been, simply, tenacity. The easy way to make every effort a winning gambit, is to never stop trying, never stop learning, and to keep striving for excellence as a moral imperative.
These characteristics are so closely inter-related for me, that they feel like facets to a singular concept, which because it lacks a commonly known label, warrants articulating them as distinct styles of leadership. For the sake of giving this collection a label, I might offer calling this style "Progressive Humanist Leadership".
Comments are closed for this story
Khan Klatt
